Improving the Rank Precision of Population Health Measures for Small Areas with Longitudinal and Joint Outcome Models
Abstract
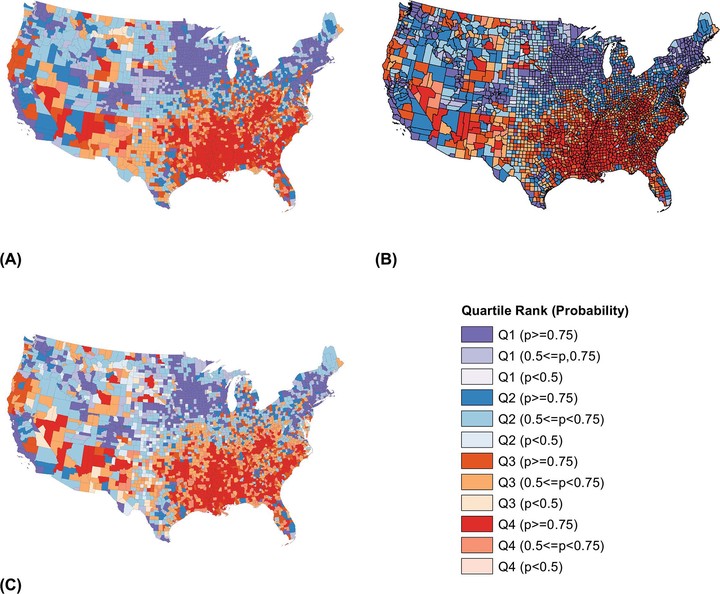
OBJECTIVES: The University of Wisconsin Population Health Institute has published the County Health Rankings since 2010. These rankings use population-based data to highlight health outcomes and the multiple determinants of these outcomes and to encourage in-depth health assessment for all United States counties. A significant methodological limitation, however, is the uncertainty of rank estimates, particularly for small counties. To address this challenge, we explore the use of longitudinal and pooled outcome data in hierarchical Bayesian models to generate county ranks with greater precision. METHODS: In our models we used pooled outcome data for three measure groups: (1) Poor physical and poor mental health days; (2) percent of births with low birth weight and fair or poor health prevalence; and (3) age-specific mortality rates for nine age groups. We used the fixed and random effects components of these models to generate posterior samples of rates for each measure. We also used time-series data in longitudinal random effects models for age-specific mortality. Based on the posterior samples from these models, we estimate ranks and rank quartiles for each measure, as well as the probability of a county ranking in its assigned quartile. Rank quartile probabilities for univariate, joint outcome, and/or longitudinal models were compared to assess improvements in rank precision. RESULTS: The joint outcome model for poor physical and poor mental health days resulted in improved rank precision, as did the longitudinal model for age-specific mortality rates. Rank precision for low birth weight births and fair/poor health prevalence based on the univariate and joint outcome models were equivalent. CONCLUSION: Incorporating longitudinal or pooled outcome data may improve rank certainty, depending on characteristics of the measures selected. For measures with different determinants, joint modeling neither improved nor degraded rank precision. This approach suggests a simple way to use existing information to improve the precision of small-area measures of population health.