A flexible method for identifying spatial clusters of breast cancer using individual-level data
Abstract
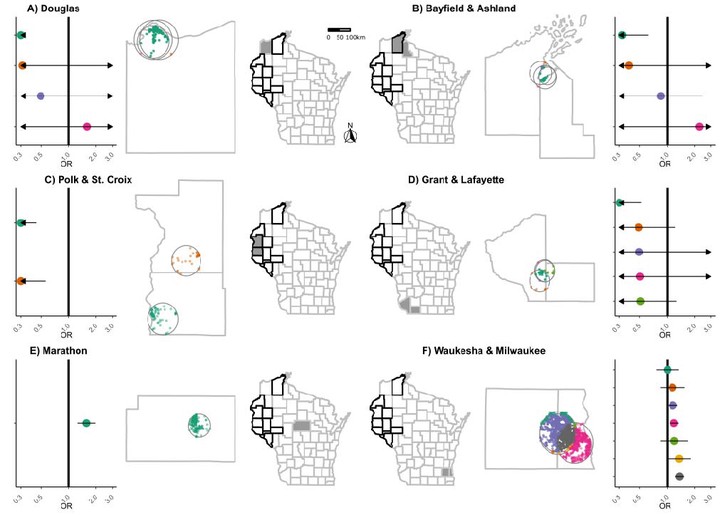
Prior research has shown that cancer risk varies by geography, but scan statistic methods for identifying cancer clusters in case-control studies have been limited in their ability to identify multiple clusters and adjust for participant-level risk factors. We develop a method to identify geographic patterns of breast cancer odds using the Wisconsin Women’s Health Study, a series of 5 population-based case-control studies of female Wisconsin residents aged 20-79 enrolled in 1988-2004 (cases=16,076, controls=16,795). We create sets of potential clusters by overlaying a 1 km grid over each county-neighborhood and enumerating a series of overlapping circles. Using a two-step approach, we fi=t a penalized binomial regression model to the number of cases and trials in each grid cell, penalizing all potential clusters by the least absolute shrinkage and selection operator (Lasso). We use BIC to select the number of clusters, which are included in a participant-level logistic regression model. We identify 15 geographic clusters, resulting in 23 areas of unique geographic odds ratios. After adjustment for known risk factors, confidence intervals narrowed but breast cancer odds ratios did not meaningfully change; one additional hotspot was identified. By considering multiple overlapping spatial clusters simultaneously, we discern gradients of spatial odds across Wisconsin.